So I decided to try and build a full blown web app using the various tools Dojo provides. I wanted to try out the feed reading data store, the grid control, some of the form dijits (Dojo widgets), and the tab control. After some thought, I ended up deciding to write an application that would allow you to compare the writing styles of different blogs and see if they had the same author. This idea had been on my “backburner list” since around 2003 when I read an interesting article on the subject called “Bookish Math”.
The field of study that deals with examining artistic works to determine authorship is called Stylometry. The theory is that each of us has a unique and identifiable way of doing something. For writing, many of the newer techniques involve examining the how often we use common words. From “Bookish Math”:
“People’s unconscious use of everyday words comes out with a certain stamp,” says David Holmes, a stylometrist at the College of New Jersey in Ewing. Precisely because writers use these function words without thinking about them, they may offer more reliable fingerprints of a writer’s style than unusual words do.
“Rare words are noticeable words, which someone else might pick up or echo unconsciously,” Burrows says. “It’s much harder for someone to imitate my frequency pattern of ‘but’ and ‘in’.”

The article goes on to talk about how frequency analysis of certain words in the “Federalist Papers” supported the idea that Madison wrote them instead of Hamilton, how an analysis on the 15th Wizard of OZ Book (billed as Frank L. Baum’s last book) revealed that it wasn’t really written by him, and how various other works can be clearly distinguished from an analysis of common words.
Since counting up common words is rather trivial, I decided to see if I could read in some blog feeds, find the frequencies of their common words, and then compare these frequencies to other blogs to see if I could determine authorship. Unfortunately, this rather naive approach didn’t come out as well as I hoped. After the app was tested, none of the numbers seemed to really stand out.
For blogs that should be similar (like this one and my livejournal), I found the common word frequencies to vary somewhat significantly. I only had overlap on around 10-20% of the words, and I wasn’t sure if that was a statistical coincidence. I also used one other person’s professional and personal blog and found similar results. I then tried to do a little original research and implemented the following alogrithm:
- Find the frequencies of the 50 most common words in the blog’s first 1,200 words.
- Find the frequencies of the 50 most common words in the whole document.
- Compare the two lists and dub the words that have similar frequencies “pattern words” – words that the person seems to use with a consistent frequency.
- Compare the “pattern words” in different blogs and see how well they overlap.
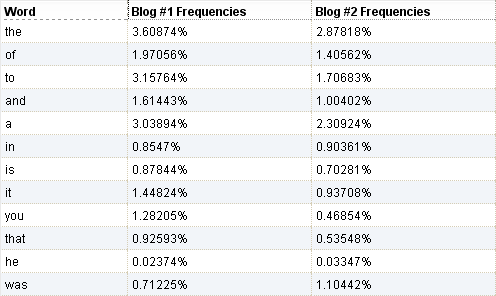
That worked a better, but I still couldn’t get completely accurate results. So the algorithm still needs a lot of work. Below you can see a small sampling of the frequency results from this blog vs my old livejournal. A frequency of 1% would mean that word makes up 1% of all of the words that were typed.
As for the Dojo side of things, I ended up really liking the slick look of the dijits. I also liked how I didn’t have to host any of the Dojo files myself, I could simply use the ones posted at the AOL Developer Network.
However, I wasn’t too happy that Dojo caused the page to take 3-4 seconds to load. And the odd sudden change from normal widgets into dijits in front of the user was kind of odd. I’m not sure if there’s a way to avoid that. This might be because I’m using a lot of Dojo tools and the Dojo library is 1.6MB gzipped. Not everything is downloaded, only what you use, but I ended up using quite a few of its tools.
Other issues I ran into were:
- There’s a bug in the grid control that effects IE7 users. The grid text doesn’t appear in IE7 if the div containing the grid has anything other than “left” for the “text-align” style property.
- You can’t create Dojo grids in divs that have their “display” property set to “none”. This bothered me because I originally wanted the grid containing the frequencies to “fade-in” after the user hit the “Process Data!” button.
Despite the short comings of my algorithm and some of app’s bloat, I decided to post it up anyway. You can view it here: Blog Stylometry Tool (note: I commented out the analysis side of things – so all it does is spit back a table of word frequencies)
I’ll most likely end up slimming down on the amount of Dojo that it uses to increase load time. Either that, or I’ll try and figure out a way to defer some of the load time. The majority of the loading time is coming from setting up the grid.
Patrick,
Keep me up do date on your work. This stuff fascinates me. I didn’t know about Bookish Math – I’ll have to read it. I come at it from the Shakespeare side. About three or four years a long lost “Funeral Elegy” was declared Shakespeare’s by Donald Foster. It caused a huge controversy. The Elegy was eventually identified as being by John Ford. (I was among the first to say it was by Ford – but not being *in* with Shakespeare Scholars – I’m just a carpenter hack – I got and get no credit.
Donald Foster, in the meantime, went down in flames – in an ugly way. He used a program called Shaxicon to identify the Funeral Elegy – claiming that the stylometric analysis “proved” it was by Shakespeare. Foster, presumably in a petulant fit of pique, never released Shaxicon into the public sphere after “his” assertions were roundly and soundly “debunked”. Shakespeare scholars are a vicious bunch, let me tell you…
Google “Donald Foster” and Shaxicon, you may turn up some interesting stuff.
I’ve read the book by Brian Vickers (mentioned in the article you linked to). Common words is a starting point, but the use of conjunctions, prepositions and certain syntactic constructions comes next. That’s hard to program into a computer.
If I had your software, I would analyze Funeral Elegy and a random patch of Shakespeare – as a sort of control.
But…
Gotta’ get to work.
Patrick Gi… forget it, you know my name…
I did some googling on “Donald Foster” and it looks like he did some work in the anthrax case that happened after Sept. 11, and ended up getting sued for defamation. He also screwed up in his analysis the JonBenet Ramsey case. He looks like an opportunist who let his ego go to his head. It sucks that he made a name for himself in the field early on, it make all of the legit people look bad.
Examining the syntax would be kind of hard, I’d have to think awhile before I decided to do that (to see if it was worth it and to come up with a fast technique).
//Examining the syntax would be kind of hard//
It depends. For example:
– Commas after conjunctions like “and”. Some people use them in a series, some don’t.
– Contractions – Some don’t & some ‘do not’.
– The use of ‘that’ as opposed to’which’.
– The number of prepositions per sentence.
– The frequency of adverbs (look for -ly words).
These ought to be easier look for.
As for Don Foster. Yeah… I think his ego got the better of him. He seems to have a tin ear for intangibles too. Anybody familiar with Shakespeare knew that the Funeral Elegy didn’t *sound* like Shakespeare. Every writer possesses a certain sound that his hard to quantify and nearly impossible (it would seem) to translate for a computer.
Don’t know if you saw this site:
http://www.shaksper.net/archives/2002/0172.html
I didn’t see that site. It looks like they had an interesting project going on, but when I visit the link they’re talking about, it says its under construction and offers to sell the domain to interested buyers :/. It’s interesting to see that other people out there are trying to develop open stylometry software. It is discouraging when you read about this stuff and then find out you can’t actually do anything yourself because the software is all proprietary or hidden away somewhere.
As for syntax, some of it would be easy to parse, but when I start doing that, I start getting a little into the research side of things (which is good and bad) since there doesn’t seem to be any clearly developed metrics on how to differentiate styles. Finding the frequency of adverbs might be interesting though.
Pat,
Are you sending the libraries as a gzip stream? Sending proper cache headers will also help a great deal (on subsequent loads).
1.6mb is still pretty big for scripts though. Your app takes 5.6 seconds to load on my slow work computer. I’ve always found Dojo to be a bit slow — it takes about 2 full seconds to sort a column on that datagrid wijit.
Maybe the newer versions (with the Sizzle core) will be faster? A year or so ago, I was looking at Dojo and ExtJS for a rich app. I ended up not doing the project, but I wasn’t very impressed with either lib. I hate to plug jQuery again…but it really is that good. 🙂
sloat – I’m not sure what you mean by sending them as a gzip stream. I’m linking to the ones hosted at the AOL Developer Network. I’m not hosting any of the Dojo files. The ones at AOL are also (from my understanding) compressed.
I may end up mixing Dojo with other libraries, since I think some of their stuff looks pretty cool, however, 5.6 seconds is way too slow. If I remove the grid it usually loads pretty quickly (I don’t have any exact numbers though), so I might look into using a grid-like control from another framework.
It’s interesting that you bring up Ext JS. The same publishing company that gave me the Dojo book recently offered me a book on Ext JS. I’m guessing they’re doing this as part of a grass roots campaign. Since it’s a good excuse to learn another framework I took them up on the offer. I may end up doing my own Dojo / Ext JS comparison, though right now I’ve barely even started this new book. It sucks to hear you weren’t impressed with Ext JS though.
jQuery is something I really want to learn. Eventually I’ll get to it.
It’s mainly that I wasn’t impressed with the license of ExtJS. For one, I don’t understand how they can do a closed-source javascript. And second, I hate it when libraries are released under the GPL and not LGPL.
It has a bunch of decent widgets, but most of it is stuff I don’t really need.
Anyway, what I meant about the gzip stream — you can actually compress scripts and css with gzip and most (if not all) modern browsers will decompress it on the client side.
http://www.julienlecomte.net/blog/2007/08/13/
That page has a link to a PHP script that will handle it if you have the zlib extension enabled. There’s also an Apache extension (mod_gzip) that will handle all of it for you.
I’m not a big fan of the GPL license either. Using that license basically means I’d never be able to use that library at work (they’d opt for a different framework). Also, according to wikipedia, it appears there’s been a lot of controversy about the licensing issues. It looks like they originally wanted a form of LGPL, but they wanted to add extra restrictions.
Thanks of the link on the compression stuff, I’ve read about the YUI compressor, but I haven’t ever used any of the compression software for the stuff I’ve written.