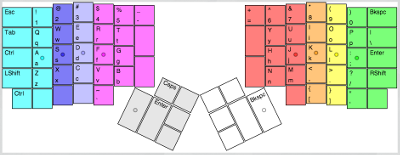
Sample ANSI art by Roy/SAC
Most people know what ASCII Art is – its art created by arranging text into pictures. ANSI art is also text art, but it’s a little more special. It allows you to create text art that includes additional text characters, color, and limited animation. It gained popularity in the tech underground of the mid-80’s, and a community of artists emerged and flourished. It’s hay day was short lived though. In the 90’s unicode became the standard for encoding text, and since ANSI Art was based on IBM’s extended ASCII* character set, its presence became more and more uncommon.
These days the most editors can’t open ANSI Art files. If you try to view them they just wind up looking like gibberish. This doesn’t mean the art form is dead though – fans of the genre have gone out of their way to create special editors and viewers so that the art can still be appreciated, but the community is much smaller than it once was.
The Lost Fonts
About a year ago, someone named Aaron Haun sent me a zip containing over a hundred user created ANSI art font files from an old DOS app called TheDraw. He thought I might be able to provide a place to preserve them since I’d done so for the AOL Macro fonts. The only problem was neither of us knew how to decode the files within the zip.
Aaron’s ASCII Tattoo
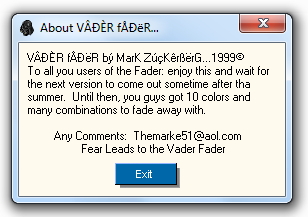
Armed with copies of TheDraw and ACiDDraw, I decided to do some ASCII archaeology. I ended up going through the same rigmarole I did when I was trying to get Mark Zuckerberg’s Vader Fader to work, and was able to load up the old DOS apps on a Windows 98 virtual machine. This unfortunately didn’t help much, but it was cool to see the old apps in action.
After some more research, I learned most of IBM’s Extended ASCII characters had unicode counter parts. Since unicode is easy to display, I wrote a script to process the font files and return unicode compatible versions. This script also stripped out the color information. Though I felt the colors were neat, I couldn’t figure out how TheDraw was encoding them**.
What was left were some pretty neat ASCII fonts from the late 80’s / early 90’s. Created for use in emails and on old BBS systems, today it appears these fonts have mostly disappeared from the internet. After talking with Aaron, the only two sites that appear to host ANSI art font files are archives.thebbs.org and slbbs.com, and in both cases you’ll need a special ANSI art viewer. Aaron told me he originally grabbed the font zip from ASCII Artist Roy/SAC’s web page (roysac.com), but that site appears to have been shutdown a year ago. Roy/SAC does still have a deviantart page though, and you can see what his site used to look like at the internet archive (NSFW-ish).
With the fonts in hand, I decided the best thing I could do was convert them into FIGlet fonts so people could once again start using them. I created simple web-based FIGlet Editor to assist in the process, and ported over the fonts I felt looked best going from ANSI to FIGlet. Sadly this means I only ported over a hand full (10 total), since a lot of ANSI’s charm is in its color. Plus, even with the decoded files and my editor, it took a decent amount of time to make the fonts.
You can see what the ported over fonts look like in the screen shot below or you can browse the “ANSI FIGlet Fonts” section of TAAG and use them yourself. Later this week I’ll also add them to the figlet.js repo if you want to download the individual figlet files.

You can see what the originals look like on Roy/SAC’s old font page (internet archive link). At some point it might be interesting make something that would show the ANSI fonts as they once were, but for now I thought it’d be cool to at least provide a way to use some of them in a stripped down form.
More ANSI Art
- ANSI Art Gallery Video – Video on a ANSI art gallery that happened a while back.
- Sixteen Colors – A site dedicated to ANSI art.
- blocktronics ACiD trip (NSFW-ish) – The longest ANSI scroller ever.
Notes
* This is somewhat confusing because there’s an extended version of ASCII known as ANSI that was done by Microsoft. This leads me to believe that the name ANSI art was a mistake that wasn’t noticed until it was too late (plus “IBM Extended ASCII Art” doesn’t have much of a ring to it). Making this even more convoluted, Microsoft’s ANSI character extension was never standardized by ANSI, so it makes no sense to call it ANSI in the first place.
** TheDraw didn’t encode colors with ANSI escape codes.
2014.01.22 Edit: I updated the font screen shot to include all of the fonts instead of just 4.
2014.05.18 Update: Roy/SAC has recently relaunched his site and created a neat tool for working with fonts from TheDraw.