Have you ever wondered what your Facebook likes say about you? And if there are any people whose posts you seem to favor? I was curious, so I decided to dig around and see if I could find some stats for likes. I couldn’t, so I decided to turn to the Facebook API. Unfortunately its like information seemed limited for privacy reasons*. Next I tried to get the information from the export feature Facebook offers. Sadly it didn’t have this data either. However, the activity log page chronicled my like history and was just what I was looking for.
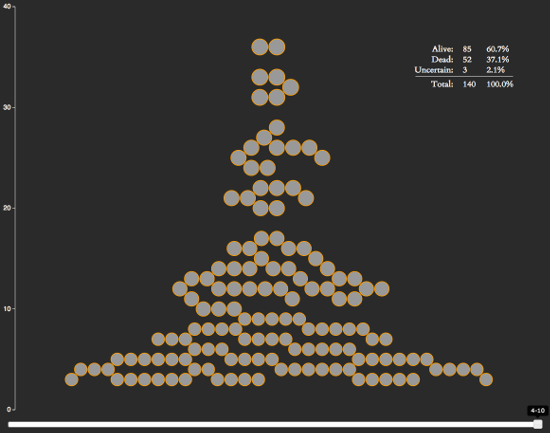
I loaded as much information from this page as I could (for some reason it breaks for me around March 2012), and saved it off to a file. I then wrote a quick script to process the data and plugged my activity log into it. The results that were spit out stated that over the past two years I’d liked 1,088 posts and that of my 133 friends, half of my likes were going to just 5 of them (~4%).
Even more interesting, these 5 people were all family members. I’m not sure if that’s just a side effect of me interacting with my family more than my friends, if my family just posts a lot, or if I’m just ignoring my friends. Whatever the case, I didn’t realize I had such a bias with my likes. Though then again, if my Activity Log wasn’t broken for the pre-2012 time period, I wonder if the results would have been different. I had my first child in 2012, and I like most pics with him in it, so that could have been skewing the results. Also, come to think of it, my dog died last year and I went back and liked a lot of pictures of him in it, so that could be skewing things too.
Though peculiar, I’m only one data point, so an analysis of my data doesn’t really say anything about anyone else. If you’re curious about your own liking biases, I’ve put the script online as a gist.
Other Analysis
I’m not the first person to want to analyze their data. Wolfram Alpha has an online app that does an in-depth analysis of a person’s Facebook data. And while it delivers a treasure trove of neat information (example: my friends fall into 5 different groups of connected users), it fails to say much about likes.
Other, less public tools**, have been developed to comb through this like data though. Dr. Jennifer Golbeck gave a Ted Talk last Fall on what your likes say about you and how they’re used by companies. In it she mentions how researchers were able to correlate IQ with people who liked the Facebook page “Curly Fries”. She also mentions how many other attributes such as sexuality and religion can be predicted to a high certainly based on what you like.
It’s probably a no-brainer big companies like Facebook and Google are mining this info for ad purposes. I couldn’t find information on Facebook’s analysis, but Google actually provides a page where you can see what they think of you. However, it’s pretty simple, and I’d be surprised if that was all they had.
Conclusion
I’ve only done a simple analysis of my own data, so there’s a lot more to say for this subject. However, it was kind of eye opening to see where most of my likes were going. Additionally, I think it’d be interesting if there was an app you could use to analyze your own data to see what it said about you. Golbeck joked about starting a company that would sell reports about potential employees to HR people – but, I think it’d be useful if people could generate those kind of reports about themselves. It could help you learn things about your subconscious behaviors or possibly better control your online image.
* Before posting this, I revisited the Facebook API, and I think the data I gleaned from the activity log could also have been retrieved through a bunch of FQL queries. If I were to write a proper app, I’d probably try and use FQL, however, writing a script to parse the activity long was pretty quick and painless.
** I could only find studies, I couldn’t find any source code.