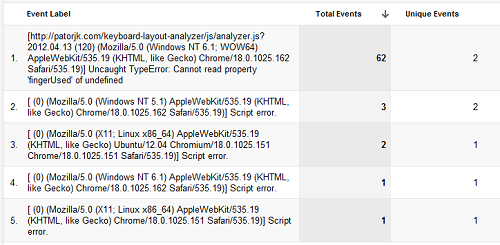
Security is a hot right now*. You see TV commercials touting degrees in Information Security, you see news stories on hacking done by Anonymous, and you hear people throwing around terms like “cyber security” and “cyber attacks”. So when offered a review copy of The Tangled Web, my interest was piqued. The book aims to take its readers on a walk through of the modern web stack, and to explain the web’s vulnerabilities and what can be done to avoid them. It’s geared at software engineers and security professionals, and is written by a security expert at Google.
The book is divided into 3 sections. The first section aims to describe the anatomy of the web. It goes over URLs, the HTTP protocol, CSS, HTML, JavaScript, non-HTML document types, and browser plugins, all with a security mind set. I felt I was pretty familiar with the URL syntax, but was surprised to learn about some of the tricky URLs that could be created. Most people probably wouldn’t think twice before visiting this URL: http://bing.com&q=test@1249763400 – what happens depends on what browser you’re using.
The second section of the book covers Browser Security, and was to me the most interesting part of the book. The fundamental security policy of the browser is the Same Origin Policy (SOP), which puts content isolation rules in place to keep web sites from interfering with one another. In most web browsers, the origin for a page is defined by its scheme, host, and port. Though apparently for IE versions before 9, only the scheme and host are taken into account – unless you’re dealing with the XMLHttpRequest (XHR) object, then IE takes all 3 into account when defining the origin.
My favorite browser flaw talked about in this section was the one on the getComputedStyle/currentStyle API. Back in 2002, it was discovered that JavaScript could be used to look at the computed color of visited links to determine if a visitor had visited a particular site. Thousands of checks could be made a second, thus any website you went to could snoop-in on your browsing habits if it wanted to. Fixes for this security issue were put in place around 2010.
Another neat trick that was talked about was trying to load an authentication-requiring image from a third party site and using the image’s onload and onerror events to see if the user had logged into that site (a good discussion of this can be found here). This idea can further be extended to third party APIs. If a website doesn’t put the proper security in place for its API, malicious sites can do all sorts of mischief to their visitors, all without them noticing.
The last section of the book is the shortest (32 pages) and focuses on coming security features. This section of the book didn’t really grab me, but there were a few bits that piqued my interest. Cross-Origin Request Sharing finally allows developers to use the XHR object in a cross domain fashion, but until older browsers are phased out, developers will have to create a fall-back behavior if they decide to use it.
Overall I enjoyed the book and found it worth reading. I do, however, wonder if framing security around a discussion of the web stack was the best way to go. The author contends that arbitrary taxonomies of vulnerabilities aren’t as informative, and that some problems don’t fit into buzzword friendly names like Cross-Site Scripting (XSS) or SQL Injection, but I think information is more accessible when organized that way. Reorganizing chapters around a taxonomy of problems like XSS, CSRF, etc, would also probably make it a better reference for developers. Though to his credit, the author does devote the last few pages to common web problems like XSS, CSRF, etc, and indicates the pages where these problems are discussed (since they come up throughout the book).
If you’re a web developer and want to get a better understanding of security I think this is a very good book and worth checking out. However, if you’re not a web developer, I wouldn’t pick this up unless you had a technical interest in web security. Lastly, if you’re interested in the book I’d recommend reading the sample chapter on the HTTP protocol, since it gives a good preview of what the book is like.
*This may be area specific. I live in Maryland, and the BRAC has been driving a lot of job growth. So it maybe it’s better to say it’s hot in the Maryland area, and possibly other places too.